Memory Is the Control Plane: Architecting AI Agents for the Enterprise
Designing Short-Term State and Long-Term Memory for Enterprise Agents

In my previous article on Agentic AI Orchestration, I outlined the broader architecture required for AI systems. This article dives deeper into the Memory section of that framework.
Most agent programs fail because memory is treated as a convenience, not an architectural discipline. Basic chat history and vector stores work well for prototypes. They fail in enterprise systems.
When orchestration spans CRMs, ERPs, and external APIs, memory becomes a strict governance problem. Four structural challenges emerge.
1. Factual Integrity vs. Semantic Similarity
Vector databases retrieve data based on linguistic similarity, not factual validity. This is dangerous in an enterprise setting. A similarity search might pull an outdated, verbose policy instead of the current, concise one simply because it matches more words in the prompt.
A “temporal control plane” manages the version history and timing of data. Without it, AI relies on outdated information that simply sounds relevant. This control plane manages:
Effective dates: When documents become officially active.
Supersession rules: Which documents replace older ones.
Version lineage: The track record of document changes over time.
Authoritative source ranking: The designated, trusted source of truth.
It guarantees the AI acts on current, valid data. Memory must separate relevance (a vector problem) from validity (a governance problem).
2. Entity Resolution and Disambiguation
Enterprise data fragments across systems with mismatched identifiers. For example: One platform stores “J. Smith.” Another stores “John A. Smith.” A third references an employee ID. A fourth uses email. Without entity resolution, agents build duplicate profiles, causing bad joins and contradictory conclusions. A governed architecture requires a deterministic system for querying a golden record.
Key identity governance rules:
Deterministic Resolution: Master Data Management (MDM) systems must govern identity using strict match rules.
No LLM Authority: Probabilistic (LLM) models can suggest matches but cannot finalize the golden record.
Agent Access: Agents only query identity via controlled APIs/MCPs; they never define it.
3. State Governance and Persistence
System memory is state, requiring active lifecycle management. Saving all interactions indefinitely pollutes the system with obsolete data.
Three controls are required:
Retention (TTL): Classify data as temporary or permanent and apply strict expiration rules.
Permissions: Enforce enterprise access controls (RBAC/ABAC) to prevent unauthorized data retrieval or storage.
Sanitization: Implement validation gates to block speculative guesses or errors from entering long-term storage.
Memory must function as a governed state machine.
4. Distributed Observability
As agents delegate tasks, causality becomes opaque without distributed observability. It is difficult to know why an agent made a decision or what data it used.
An enterprise-grade architecture requires:
Traceable memory access: Logging all reads and writes.
Versioned nodes: Tracking context changes over time.
Tool call lineage: Recording API and sub-agent calls.
Audit logs: Documenting the exact path to the final decision.
This tracking is mandatory for accountability and compliance.
The Memory Control Plane
Treat AI memory as a strict management system, not a quick search tool. A managed system ensures accuracy and trust. The true limit to AI success will be how rigorously we control what the models remember.
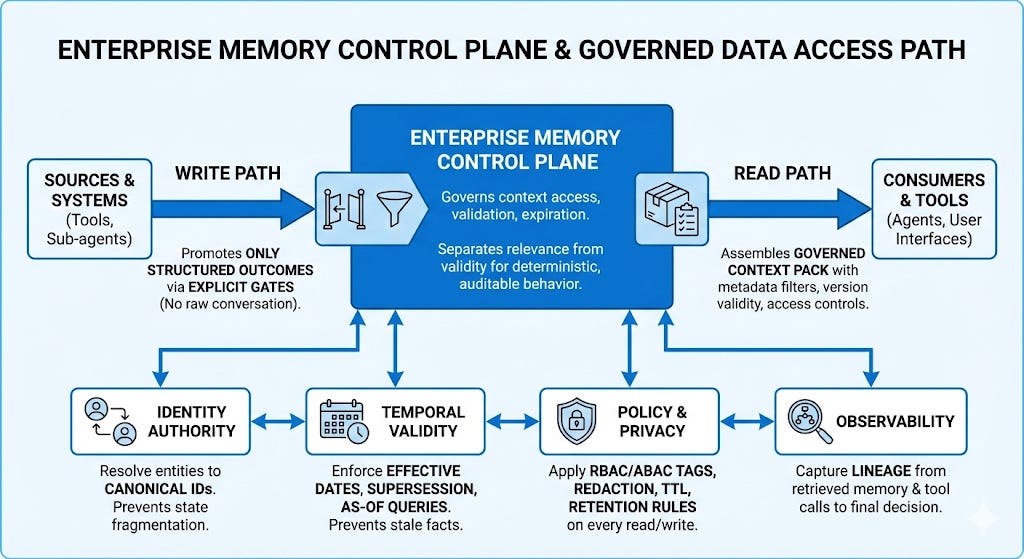
An enterprise memory control plane governs how data is accessed and saved to ensure predictable behavior. It consists of six functions:
Read Path: Retrieves data using strict filters, version checks, and access rules
Write Path: Saves only verified outcomes, avoiding raw chat logs.
Identity Authority: Links data to a single golden record to prevent duplicates.
Temporal Validity: Tracks effective dates so outdated information is ignored.
Policy & Privacy: Enforces security tags, data masking and anonymization.
Observability: Logs data and tools used for decisions.
Two Memory Categories
Enterprise AI use cases fall into two categories: document-centric and network-centric. Understanding this difference prevents architectural mistakes.
Document-Centric Memory
For example, a brand lead asks whether a campaign complies with updated regulatory guidance. The answer lives inside a bounded set of documents. The failure risk is not missing data. It is breaking logical qualifiers during chunked retrieval. The solution is hierarchical retrieval, metadata filtering, and version control. This is a document centric problem.
Network-Centric Memory
For example, A VP asks which high-value accounts in the East coast region are at risk next quarter due to declining engagement and competitive pressure. No single document contains the answer. The agent must connect: CRM pipeline data, Market engagement signals, Competitive Intelligence, Forecast projections. The solution is not better chunking. It’s governed identity, graph traversal, and temporal lineage. This is a network centric problem
Do not try to solve both problems with a single vector database. Vectors find meaning, graphs construct meaning, and governance protects enterprise truth.
The Taxonomy of Agent Memory
Having identified the systemic risks of mismanaged memory and context, we must define the architectural components required to mitigate them. At its core, an enterprise agentic system relies on two distinct classes of memory namely Short term & Long term. The distinction is about the logic of the data and its risk profile.
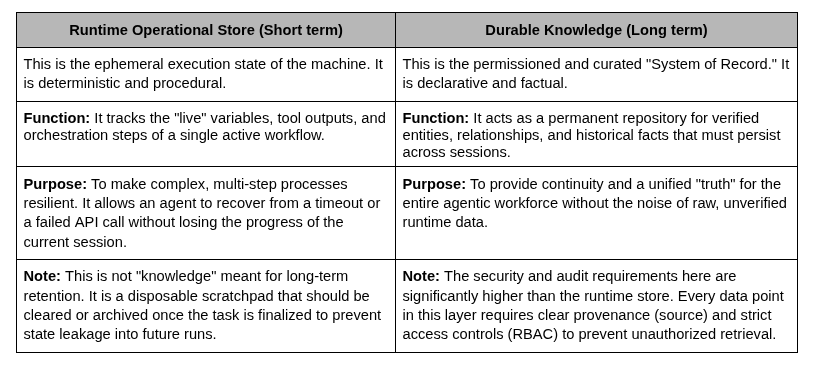
Short-Term Memory
Short-term memory turns an assistant into a reliable system.
Inference Context: What the model sees for a single step. Treat as disposable.
Session Memory: Spans a user session. Enforce expiration and redact sensitive details.
Workflow State Store: The authoritative run-state. Must be deterministic and replayable.
Tool Output Cache: Ephemeral cache for expensive calls. Apply strict TTL.
Rolling Summary Buffer: Structured state of understanding for long interactions.
Before detailing long-term memory options, outlining three vector retrieval patterns and their specific applications in long term memory.
Vector Retrieval Patterns
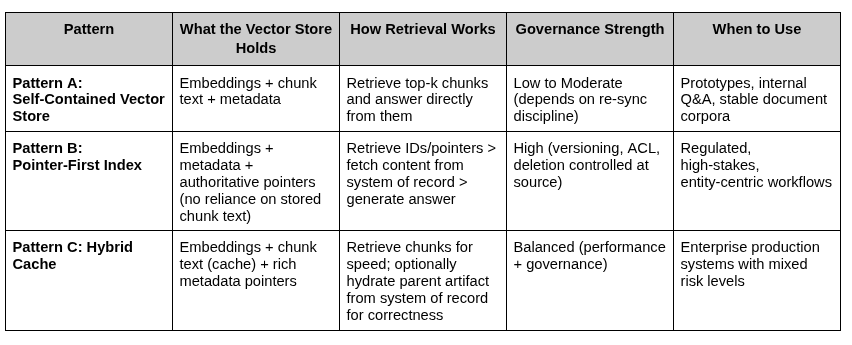
Most platforms default to Pattern A (AWS Bedrock Knowledge Bases with OpenSearch or S3 Vectors, Pinecone, pgvector, etc.) due to simplicity. Pattern C requires adding authoritative IDs and retrieving parent content from the system of record. To address latency, use asynchronous pre-fetching and cache frequently accessed artifacts. Apply strict TTL policies to prevent drift.
Long-Term Memory
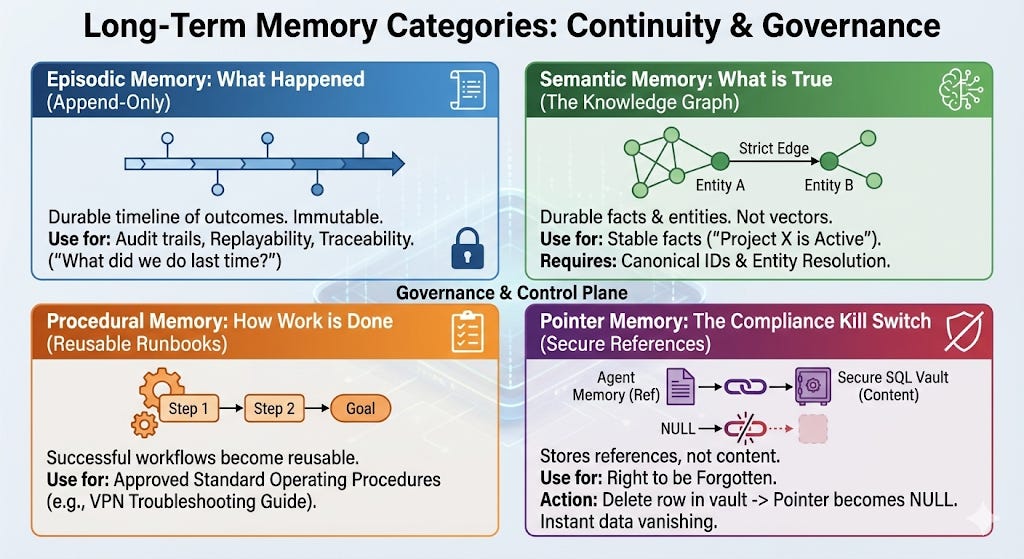
Long-term memory provides continuity without uncontrolled retention.
Episodic Memory: Durable timeline of outcomes stored in an append-only event store. Use Pattern B or C to maintain reproducibility and auditability.
Semantic Memory for
Documents: Durable knowledge in policies and reports. Maintained in a versioned document repository. Use Pattern A for low-stakes, C for high-stakes.
Entities: Canonical entity state. Governed by MDM or graph stores. Use Pattern B to ensure deterministic entity truth.
Procedural Memory: Approved workflows and runbooks. Version-controlled. Use Pattern B or C because procedures must be exact.
Pointer Memory: Secure references to sensitive content, enabling hard deletion. Use Pattern B to ensure strict policy boundaries.
Promoting Short-Term to Long-Term Memory
The biggest failure is promoting raw conversation into durable stores. Promotion must be gated and outcome-driven.
Document-Centric Promotion
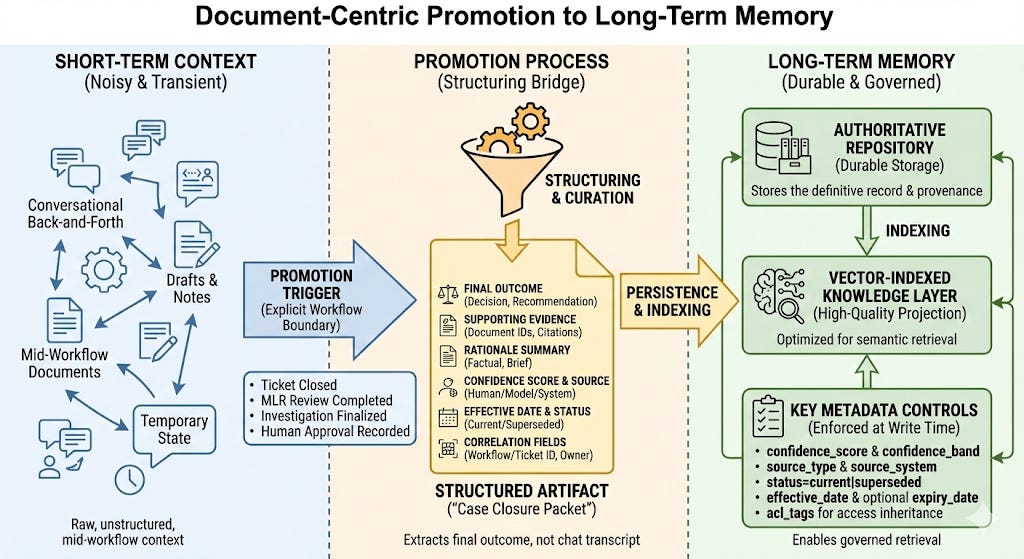
The goal is to create a durable, governed artifact.
Trigger: Must happen at explicit workflow boundaries. For example: Ticket closed or case resolved, Review completed, Human approval recorded.
Structuring Bridge: Extract outcomes into a structured record. Include final outcome, evidence, rationale, confidence score, effective date, and correlation fields. This prevents the vector store from becoming a junk drawer.
Persistence: Store the artifact in an authoritative repository and index it. Enforce metadata controls at write time to enable governed retrieval.
Network-Centric Promotion
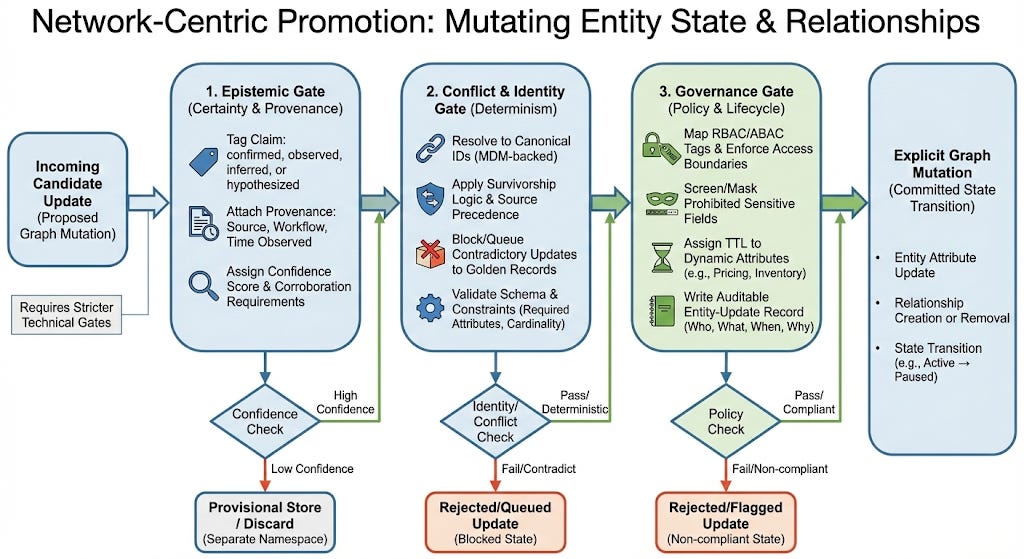
This is riskier because it mutates entity state. Document promotion produces an artifact; graph promotion produces a state transition.
Epistemic Gate: Decide the claim’s defensibility. Tag claims, attach provenance, and assign confidence scores. Store low-confidence facts in a provisional namespace.
Conflict and Identity Gate: Confirm the update applies to the correct entity. Resolve to canonical IDs, apply survivorship logic, and block contradictory updates. Validate schemas and reject if non-deterministic.
Governance Gate: Map access tags, screen sensitive fields, assign TTL, and write audit records. Only then commit mutations.
Only after these checks should the system commit an explicit mutation such as:
Entity attribute update
Relationship creation or removal
State transition (active -> paused, approved -> revoked)
Do not let AI update the main database directly. Route updates to a provisional namespace requiring strict checks or human approval and ensure rollback mechanisms exist.
Conclusion: Memory Discipline Beats Model Size
Promotion should behave like a state machine. This single framing keeps memory clean over time.
As models improve, memory discipline is the limiting factor for enterprise agents.
Treat memory as a control plane.
Separate document-centric from network-centric workflows.
Persist structured outcomes, not raw conversation.
Start with document-centric use cases. Introduce Pattern C for high stakes. Add semantic graphs only for multi-hop joins. Finally, instrument observability from day one.
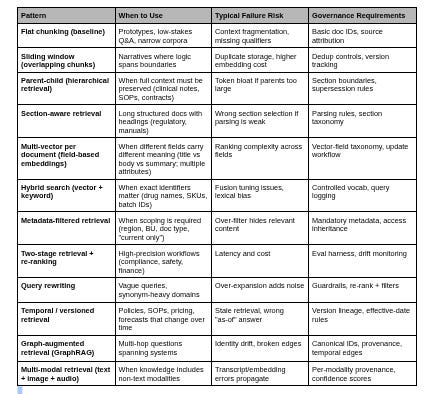
Sidebar 1: Vector Retrieval Pattern Matrix
Selecting a pattern is a risk and governance decision. Ask where truth lives, what the cost of failure is, and if time matters. A safe default stack uses hybrid search, metadata filtering, hierarchical retrieval, and optional re-ranking. Flat chunking is only for prototypes.
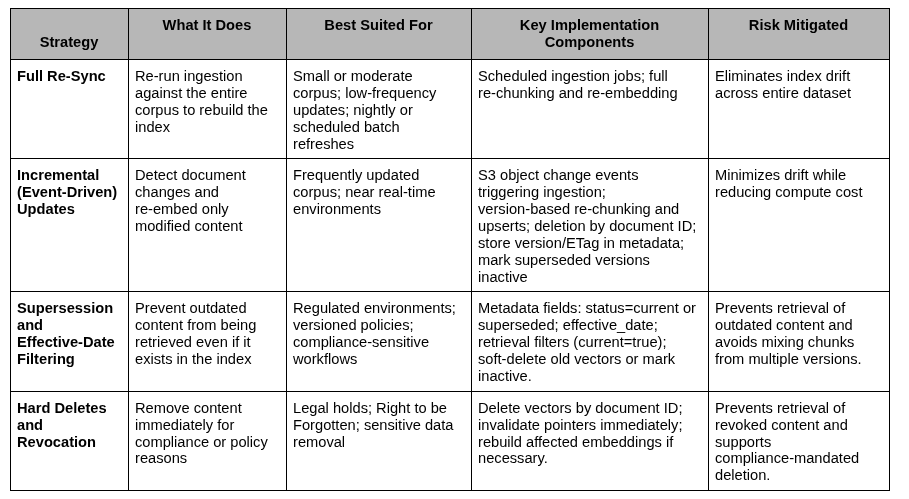
Sidebar 2: Keeping Vector Indexes Fresh Over Time
Great read